使用生产者消费者模式获取 CyPress 数据
一直都直到有“生产者-消费”者这个模型,但是从来都没有尝试编写过,最近正好在调试 CyPress FX3 系列的一款芯片,下面是编写上位机过程中的一些记录。
背景介绍
CyPress FX3 是一些列的 USB3.0 芯片,在我们的项目中用来完成 FPGA 和 电脑之间的数据通讯,之所以选择 CyPress 系列的芯片是因为使用其 USB2.0,用起来较为方便。
数据分为上行和下行两个方向,下行主要是向 FPGA 发送命令,这个数据量不是特别大,对传输速度也没有要求,也就是所谓的慢控制信号;上行数据就是 FPGA 需要打包送到 PC 端的数据,这部分数据的数据量不定,根据不同的前端类型,数据量可能很大,也可能很小,但是都有一个要求,数据堆积不能太多,必须要及时传输到 PC 端。
最简单的单线程做法是:获取数据 -> 写硬盘 -> 获取数据 -> 写硬盘;这个过程致命的缺点就是花大量的时间在等待写硬盘上,写硬盘的速度本身就很慢,加上每次获取的数据量可能都很小,再小文件写硬盘速度就更慢了。
因此需要使用生产者消费者模型来对数据进行获取。
生产者消费者
单线程数据获取模式
先从单线程模型开始讲起,下面是最初版本的数据获取代码。
首先是以追加模式打开文件,然后调用 usbInterface.DataReceive() 方法来获取数据,如果读回了数据,该方法会返回 true,之后就可以将读回的数据写文件,然后再开始下一次读数。
private void GetSlowDataRateResultCallBack(MyCyUsb usbInterface)
{
bw = new BinaryWriter(File.Open(filepath, FileMode.Append));
//private int SingleDataLength = 512;
bool bResult = false;
byte[] DataReceiveBytes = new byte[512];
while (StateIndicator.SlowAcqStart)
{
bResult = usbInterface.DataRecieve(DataReceiveBytes, DataReceiveBytes.Length);
if (bResult)
{
bw.Write(DataReceiveBytes);
}
}
bw.Flush();
bw.Dispose();
bw.Close();
}
这个模式最大的问题在于每次获取了数据之后要等写文件,等文件写完了再获取下一次数据,这个流程中最大的问题在于每个时刻总有一个过程在等待,写文件的时候数据获取方法在等待,获取数据的时候写文件的方法在等待,如果在写文件的时候有大量的数据来了,又不能被读走,就会把 FPGA 内的存储写满,此时再来的新数据就只能被丢弃。
在最初的上位机版本中总是认为是写文件太慢了,实测之后发现获取数据的方法不同,速度也不同,在后面介绍 USB 读数方法的时候会介绍两种读数方法。
现在的问题就是一个方法卡住了,另外一个方法也就不能再继续工作了,很自然的就想到了将获取数据和写文件拆成两个独立的线程,这就是生产者消费者模式。
生产者消费者模式
基本思想
生产者消费者模式的思想非常简单,首先是有一个生产者的线程,在这里就是从 USB 接口获取数据的线程将获取到的数据写入缓冲区 (Buffer) 中,然后消费者线程,也就是写文件的线程从缓冲区中取数,将得到的数据写文件,两个线程相互独立,大部分时候不需要互相等待。
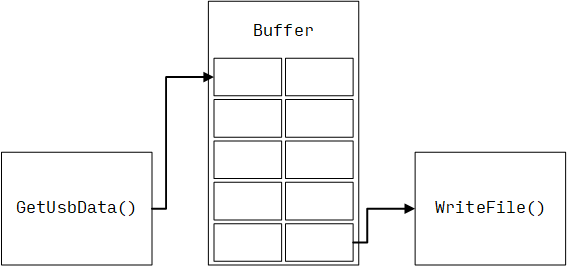
当然,这里有个最大的疑问——写文件的线程太慢了,Buffer 写满了怎么办?在生产者消费者模式中,Buffer 写满了生产者就要停下来,等 buffer 有位置了再继续产生数据,这就是在生产者消费者模式中需要等待数据的地方。这个回答可能不够满意,因为存在一种情况,生产者不能停,一停就会丢数,这种情况下要做的就是换接口,因为整个数据链路上的瓶颈在于写文件,说明是接口不合适,应该换用其他接口比如以太网协议之类的,将数据分发到多处进行存储。
C# 中使用生产者消费者模式
在 .NET 4.0 中新增了一个用于线程安全的类 BlockCollection
这个类最常用的两个构造器是 BlockingCollection() 和 BlockingCollection(Int32),前一个例化一个 BlockCollection 对象但是不指定大小,后一个指定 BlockCollection 的大小。
在 USB 通讯的例子中先例化一个 ThreadBuffer
BlockCollection<byte[]> ThreadBuffer = new BlockCollection<Byte>(500)
生产者向 BlockCollection 中添加数据使用 Add 方法,如果在例化 BlockCollection 的时候指定了大小,在调用 Add() 方法的时候如果 BlockCollection 存不下了,这个线程就会被阻塞,直到 BlockCollection 有空间存储。
public void Add (T item);
消费者从 BlockCollection 中获取数据可以使用 Take() 方法,如果 ThreadBuffer 是空的的话,消费者会被阻塞,直到 ThreadBuffer 中有数据。
public T Take ();
上面提供了消费者和生产者所需要的最基本的方法,接下来就是要处理线程结束的问题了。数据产生总有一个结束的时候,在生产者线程结束之前,需要调用 CompleteAdding() 方法,通知消费者数据产生已经结束。相应的消费者需要查询 IsCompleted 属性,如果 BlockColleteion 被标记为添加完成,同时是空的时候,IsCompleted 为真,这个时候消费者线程就可以结束了。
除此之外 BlockCollection 还提供 IsAddingCompleted 属性,用来标记 生产者是否完成添加,这个属性大部分时候都用不到。当USB 被意外拔掉的时候,生产者可能来不及标记 CompleteAdding(),这个时候可以先查询 IsCompleted 然后再决定要不要补上 CompleteAdding() 方法。
一个完整的实例代码应当如下:当开始按钮按下之后判断现在是要开始采集还是结束采集。开始采集首先是新建一个 BlcokCollection 的对象,将 ThreadData 指向这个对象用来存储数据,然后从 UI 界面获取 BufSize, QueueSize 和 Package per Xfer 参数,这三个参数会在 USB 部分进行解释。然后就存文件,并且用 BinaryWriter 对象指向这个文件;然后就可以写存文件的线程了。
这里用 Task.Run() 运行一个消费者线程,先判断 ThreadData 是不是被生产者标记为完成且已经为空,如果没有就从里面取出一个数据,然后写文件。注意:如果 ThreadData 空了 BlockCollection 类会自动阻塞这个线程。
当消费者完成所有数据的添加,并且 ThreadBuffer 已经为空,消费者线程就可以结束了,结束之后将缓冲区写道文件里,并且关闭文件。
在之后就是启动生产者线程,生产者线程的具体实现会在 USB 部分详细介绍,主要是参考了 CyPress 的 Stream 软件的写法。
private void btnStartAcq_Click(object sender, RoutedEventArgs e)
{
if (btnStartAcq.Content.Equals("Start"))
{
btnStartAcq.Content = "Stop";
btnStartAcq.Background = new SolidColorBrush(Color.FromRgb(181, 93, 76));
btnSetUsb.IsEnabled = false;
ThreadData = new BlockingCollection<byte[]>(500);
BufSz = BulkInEndPoint.MaxPktSize * short.Parse(cbxPpx.Text);
QueueSz = int.Parse(cbxXferQueue.Text);
PPX = int.Parse(cbxPpx.Text);
if (!SaveFile())
{
return;
}
BinaryWriter bw = new BinaryWriter(File.Open(AbsoluteFileName, FileMode.Append));
bRunning = true;
var saveTask = Task.Run(() =>
{
byte[] DataToFile;
while (!ThreadData.IsCompleted)
{
item = ThreadData.Get();
DataToFile = item;
bw.Write(DataToFile);
}
bw.Flush();
bw.Dispose();
bw.Close();
});
Thread.Sleep(1000);
var producerTask = Task.Factory.StartNew(() => DataProducer());
}
else
{
btnStartAcq.Content = "Start";
btnStartAcq.Background = new SolidColorBrush(Color.FromRgb(27, 129, 62));
bRunning = false;
btnSetUsb.IsEnabled = true;
}
}
上面的生产者和消费者分别使用了 Task.Factory.StartNew() 和 Task.Run() 两种方法,实际上在 .NET 4.5 之后都用 Task.Run 就可以了,剩下的交给 Task 去处理就好了。
另一个版本的消费者
BlockCollection 还提供另外一个方法 GetConsumingEnumerable(),看名字就知道这个方法的作用,获取一个可枚举的对象,这个用法就更加灵活了,上面消费者线程就可以改成这样,直接用 foreach 语句完成消费者的数据获取,当 ThreadData 完成之后,foreach 语句跳出。
var saveTask = Task.Run(() =>
{
byte[] DataToFile;
foreach(var item in ThreadData.GetConsumingEnumerable())
{
item = ThreadData.Get();
DataToFile = item;
bw.Write(DataToFile);
}
bw.Flush();
bw.Dispose();
bw.Close();
});
CyUSB.dll
下面主要是用 CyUSB.dll 的方法实现生产者线程
提供 CyAPI 供大家调用,在传输数据中主要使用的是两个方法:同步的 XferData() 或者 BeginDataXfer(), WaitForXfer() 和 FinishDataXfer() 构成的异步方法,CyPress 极力推荐使用 XferData(),但是 XferData 的效率确实不高。
XferData
需要先设置好 timeout 的时间,即 EndPoint.TimeOut。以 ms 为单位,默认是 10s
XferData 需要指定方向,参数为 XferData(ref byte[] data, ref int len, bool dir),其中的 dir 就是方向,其有一个两参数的重载 XferData(ref byte[] data, ref int len),不带方向参数,默认是 in。
虽然在手册里说如果不是控制的 EndPoint 方向由 EndPoint 的方向来指定,即 BulkOutEndPoint 的方向就是 out,BulkInEndPoint 的方向就是 in,但是如果调用 BulkOutEndPoint.XferData(ref byteArray, ref length),下位机根本收不到数据,如果加上方向参数 BulkOutEndPoint.XferData(ref byteArray, ref length, trure) 就能正常发数。
根据 CyPress 论坛的一个帖子,length 的长度最大是 4M,但是我目前没有找到官方文档的出处,CyPress Stream 上位机也是限制的最大传输块为 4M。
这个函数我没有跑太快,原因可能是因为 length 设置的太小了,后面测了更大的 length 再来放结论。
异步方法
异步方法由 3 个部分组成,BeginDataXfer(), WaitForXfer() 和 FinishDataXfer(),除了第二个方法可以设置 timeout 参数以外,其他方法都是立刻返回,这三个方法必须依次调用,FinishDataXfer 会返回是否获取到数,如果获取到数起参数列表会指示有多少数,然后就可以写入 BlockCollection 类,等待消费者取数。
注意的是,如果异步生产者只开一个线程,那么和同步的 XferData() 方法并没有太大的区别,异步方法最大的作用在于可以同时发起多个通讯,然后一个一个的收数,并控制数据之间的时序,下面的代码会提到这一点。
下面一段一段的贴出异步方法的代码,并作简单解释,代码并不是原创,和 USB 交互的代码是从 CyPress Stream 的代码中提取出来的,代码的方法比较复杂,但是看懂了也就理解了 USB 通讯的过程。
生产者类
首先是生产者类,这个类是我自己封装的,在类的最开始先声明异步方法需要的 byte Suzuki,这里之所以使用二维数组是因为会开多个 BeginDataXfer(), WaitForXfer, 和 FinishDataXfer() 的线程,每个数组对应一个组合,数组的列宽 QueueSz 就是要开的线程的个数。后面一部比较关键,使用 GCHandle.Alloc 阻止 .NET 对这些数组进行垃圾回收,在我写的第一版代码里没有加这个,老是跑着跑着代码就崩溃,怀疑是这个原因,从后面的代码可以看到,这几个数组只是作为一个参数传进去了,但是并没有什么实际的作用,最后也没有任何的返回值,可能是 .NET 在某个时候把他们当成了可回收垃圾了。当然现在有一个稳定的版本了,也就没有去管老版本为什么崩溃了。
接下来的 Try 语句块里就是从 USB 接口获取数据的方法,后面会介绍,最后必须对GCHandle.Alloc 的资源进行释放,不然就死在内存里了。
private void DataProducer()
{
// Setup the queue buffers
byte[][] cmdBufs = new byte[QueueSz][];
byte[][] xferBufs = new byte[QueueSz][];
byte[][] ovLaps = new byte[QueueSz][];
ISO_PKT_INFO[][] pktsInfo = new ISO_PKT_INFO[QueueSz][];
//////////////////////////////////////////////////////////////////////////////
///////////////Pin the data buffer memory, so GC won't touch the memory///////
//////////////////////////////////////////////////////////////////////////////
GCHandle cmdBufferHandle = GCHandle.Alloc(cmdBufs[0], GCHandleType.Pinned);
GCHandle xFerBufferHandle = GCHandle.Alloc(xferBufs[0], GCHandleType.Pinned);
GCHandle overlapDataHandle = GCHandle.Alloc(ovLaps[0], GCHandleType.Pinned);
GCHandle pktsInfoHandle = GCHandle.Alloc(pktsInfo[0], GCHandleType.Pinned);
try
{
LockNLoad(cmdBufs, xferBufs, ovLaps, pktsInfo);
}
catch (NullReferenceException e)
{
// This exception gets thrown if the device is unplugged
// while we're streaming data
e.GetBaseException();
}
//////////////////////////////////////////////////////////////////////////////
///////////////Release the pinned memory and make it available to GC./////////
//////////////////////////////////////////////////////////////////////////////
cmdBufferHandle.Free();
xFerBufferHandle.Free();
overlapDataHandle.Free();
pktsInfoHandle.Free();
}
发起 USB 连接
正如这个方法的名字 LockNLoad,这个方法是为了开启 QueueSz 个 BeginDataXfer(),在方法的最开始又实例化了 几个 GCHandle,这里齐是不是很理解,在上一个方法已经足足他们被 GC 了,为什么这里还要再来一次。
先抛开这个地方,重点在于后面的代码,每个 xBufs 初始化成大小为 BufSz 的数组,其中 $BufSz = EndPoint.XferSize \times PackagePerXfer $,其中 PakcakgePerXfer 是用户指定的每次传输的数据包个数,BufSz 不要超过 4MB,否则会出现数据包顺序错乱的问题。
然后按照 QueueSz 一个一个的开始 BeginDataXfer() 发起 USB 通讯,接下来就是重载方法 XferData(),其实在这里不应该用和同步方法相同的方法名,容易引起误解。
在方法的最后,要把 GCHandle.Alloc 的对象全部释放。
public unsafe void LockNLoad(byte[][] cBufs, byte[][] xBufs, byte[][] oLaps, ISO_PKT_INFO[][] pktsInfo)
{
int j = 0;
int nLocalCount = j;
GCHandle[] bufSingleTransfer = new GCHandle[QueueSz];
GCHandle[] bufDataAllocation = new GCHandle[QueueSz];
GCHandle[] bufPktsInfo = new GCHandle[QueueSz];
GCHandle[] handleOverlap = new GCHandle[QueueSz];
while (j < QueueSz)
{
// Allocate one set of buffers for the queue, Buffered IO method require user to allocate a buffer as a part of command buffer,
// the BeginDataXfer does not allocated it. BeginDataXfer will copy the data from the main buffer to the allocated while initializing the commands.
cBufs[j] = new byte[CyConst.SINGLE_XFER_LEN];
xBufs[j] = new byte[BufSz];
//initialize the buffer with initial value 0xA5
for (int iIndex = 0; iIndex < BufSz; iIndex++)
xBufs[j][iIndex] = 0;
int sz = Math.Max(CyConst.OverlapSignalAllocSize, sizeof(OVERLAPPED));
oLaps[j] = new byte[sz];
pktsInfo[j] = new ISO_PKT_INFO[PPX];
/*//////////////////////////////////////////////////////
*
* fixed keyword is getting thrown own by the compiler because the temporary variables
* tL0, tc0 and tb0 aren't used. And for jagged C# array there is no way, we can use this
* temporary variable.
*
* Solution for Variable Pinning:
* Its expected that application pin memory before passing the variable address to the
* library and subsequently to the windows driver.
*
* Cypress Windows Driver is using this very same memory location for data reception or
* data delivery to the device.
* And, hence .Net Garbage collector isn't expected to move the memory location. And,
* Pinning the memory location is essential. And, not through FIXED keyword, because of
* non-usability of temporary variable.
*
////////////////////////////////////////////////////////////////*/
//fixed (byte* tL0 = oLaps[j], tc0 = cBufs[j], tb0 = xBufs[j]) // Pin the buffers in memory
////////////////////////////////////////////////////////////////
bufSingleTransfer[j] = GCHandle.Alloc(cBufs[j], GCHandleType.Pinned);
bufDataAllocation[j] = GCHandle.Alloc(xBufs[j], GCHandleType.Pinned);
bufPktsInfo[j] = GCHandle.Alloc(pktsInfo[j], GCHandleType.Pinned);
handleOverlap[j] = GCHandle.Alloc(oLaps[j], GCHandleType.Pinned);
// oLaps "fixed" keyword variable is in use. So, we are good.
////////////////////////////////////////////////////////////////////
unsafe
{
//fixed (byte* tL0 = oLaps[j])
{
CyUSB.OVERLAPPED ovLapStatus = new CyUSB.OVERLAPPED();
ovLapStatus = (CyUSB.OVERLAPPED)Marshal.PtrToStructure(handleOverlap[j].AddrOfPinnedObject(), typeof(CyUSB.OVERLAPPED));
ovLapStatus.hEvent = (IntPtr)PInvoke.CreateEvent(0, 0, 0, 0);
Marshal.StructureToPtr(ovLapStatus, handleOverlap[j].AddrOfPinnedObject(), true);
// Pre-load the queue with a request
int len = BufSz;
if (BulkInEndPoint.BeginDataXfer(ref cBufs[j], ref xBufs[j], ref len, ref oLaps[j]) == false)
Failures++;
}
j++;
}
}
XferData(cBufs, xBufs, oLaps, pktsInfo, handleOverlap); // All loaded. Let's go!
unsafe
{
for (nLocalCount = 0; nLocalCount < QueueSz; nLocalCount++)
{
CyUSB.OVERLAPPED ovLapStatus = new CyUSB.OVERLAPPED();
ovLapStatus = (CyUSB.OVERLAPPED)Marshal.PtrToStructure(handleOverlap[nLocalCount].AddrOfPinnedObject(), typeof(CyUSB.OVERLAPPED));
PInvoke.CloseHandle(ovLapStatus.hEvent);
/*////////////////////////////////////////
*
* Release the pinned allocation handles.
*
//////////////////////////////////////////*/
bufSingleTransfer[nLocalCount].Free();
bufDataAllocation[nLocalCount].Free();
bufPktsInfo[nLocalCount].Free();
handleOverlap[nLocalCount].Free();
cBufs[nLocalCount] = null;
xBufs[nLocalCount] = null;
oLaps[nLocalCount] = null;
}
}
GC.Collect();
}
数据传输
数据传输主要是完成 WaitForXfer() 和 FinishDataXfer(),并将数据压到缓冲区。
最开始的变量声明注意有 Successes, Failure 和 Speed,这是为了在前面板中显示用的,注意不能在这个线程中直接改变 窗口的数据,因为 Main 线程并不在这里,需要一个委托 DisplayPackageInfo(int x, int y, double z) 来完成。
接下来就是数据传输的主要部分,虽然说发起了很多个 BeginDataXfer(),但是还是一个一个的结束的,先是执行 WaitForXfer() 方法,然后再是 FinishDataXfer() 方法,如果成果的读回数据,FinishaDataXfer 会返回 ture,这个时候就可以用 ThreadData.Add() 将读回的数据压入缓冲区,注意读回的数据包可能短于数组的大小,因为 USB 可能会提交 Short Package 和 Zero Length Package,写入缓冲区的数组大小一定要按照实际读回的大小来写,否则会得到很多的 0。结束了一个传输之后马上开启下一个 BeginDataXfer(),这样子就保证了 USB 的传输队列里面一直有 QueueSz 个连接。
后面是一些数据率的计算和窗口更新的方法,不再详细解释。
方法跳出之前要结束所有 EndPoint 的传输,并且调用 ThreadData.CompleteAdding() 指示生产者读空 buffer 后就可以结束了。
public unsafe void XferData(byte[][] cBufs, byte[][] xBufs, byte[][] oLaps, ISO_PKT_INFO[][] pktsInfo, GCHandle[] handleOverlap)
{
int k = 0;
int len = 0;
Successes = 0;
Failures = 0;
XferBytes = 0;
t1 = DateTime.Now;
long nIteration = 0;
CyUSB.OVERLAPPED ovData = new CyUSB.OVERLAPPED();
DisplayPacketInfo dp = new DisplayPacketInfo(
(int x, int y, double z) =>
{
tbxPackageCount.Text = packageNum.ToString();
tbxFailurePkg.Text = packageFailure.ToString();
tbxSpeed.Text = Speed.ToString("#0.00");
});
for (; bRunning;)
{
nIteration++;
// WaitForXfer
unsafe
{
//fixed (byte* tmpOvlap = oLaps[k])
{
ovData = (CyUSB.OVERLAPPED)Marshal.PtrToStructure(handleOverlap[k].AddrOfPinnedObject(), typeof(CyUSB.OVERLAPPED));
if (!BulkInEndPoint.WaitForXfer(ovData.hEvent, 500))
{
BulkInEndPoint.Abort();
PInvoke.WaitForSingleObject(ovData.hEvent, 500);
}
}
}
// FinishDataXfer
int FirstPackage;
int LastPackage = 0;
int PkgLength;
if (BulkInEndPoint.FinishDataXfer(ref cBufs[k], ref xBufs[k], ref len, ref oLaps[k]))
{
XferBytes += len;
//if(xBufs[k] != null)
if(len != 0)
{
byte[] DataToFile = new byte[len];
Array.Copy(xBufs[k], DataToFile, len);
//AcqDataBuffer.SetData(DataToFile);
ThreadData.Add(DataToFile);
}
Successes++;
}
else
Failures++;
// Re-submit this buffer into the queue
len = BufSz;
if (BulkInEndPoint.BeginDataXfer(ref cBufs[k], ref xBufs[k], ref len, ref oLaps[k]) == false)
Failures++;
k++;
if (k == QueueSz) // Only update displayed stats once each time through the queue
{
k = 0;
t2 = DateTime.Now;
elapsed = t2 - t1;
xferRate = XferBytes / elapsed.TotalMilliseconds;
xferRate = xferRate / (1000.0);
Dispatcher.Invoke(dp, (int)Successes, (int)Failures, (double)xferRate);
// For small QueueSz or PPX, the loop is too tight for UI thread to ever get service.
// Without this, app hangs in those scenarios.
Thread.Sleep(0);
}
Thread.Sleep(0);
} // End infinite loop
// Let's recall all the queued buffer and abort the end point.
BulkInEndPoint.Abort();
//AcqDataBuffer.SetDataDone();
ThreadData.CompleteAdding();
}
同步方法和异步方法对比
根据 CyAPI.cpp 中的一段代码,其实同步方法也是变相的调用异步方法,下面的 8, 9, 10 行就是调用单线程的异步方法。理论上来说 buffer 的大小开得一致,速度上应该没有差别,这个有空了测了速度再来补上测试结果。
bool CCyUSBEndPoint::XferData(PUCHAR buf, LONG &bufLen, CCyIsoPktInfo* pktInfos)
{
OVERLAPPED ovLapStatus;
memset(&ovLapStatus,0,sizeof(OVERLAPPED));
ovLapStatus.hEvent = CreateEvent(NULL, false, false, NULL);
PUCHAR context = BeginDataXfer(buf, bufLen, &ovLapStatus);
bool wResult = WaitForIO(&ovLapStatus);
bool fResult = FinishDataXfer(buf, bufLen, &ovLapStatus, context, pktInfos);
CloseHandle(ovLapStatus.hEvent);
return wResult && fResult;
}
如果要开多个采集线程,最好还是用异步的方法,因为每个 BeginDataXfer(), WaitForXfer() 和 FinishDataXfer(),是有顺序的,如果直接开十个 XferData() 的线程,数据之间的顺序关系就会乱了。
测试
待完成,都测过,但是测试结果还没有整理
下面的测试都是在不丢包的前提下完成,如果丢包的话速度可以上天。
同步方法传输速度
异步方法传输速度
异步方法不同 QueueSz 速度
单线程下不同 BufSz 速度
可回收垃圾
总结
- 生产者消费者线程是必须的,否则的话速度不管怎么都跑不上去
- 异步方法其实没有太大的必要,因为平时也不会跑这么快,如果跑这么快,首先是硬盘受不了,其次是采用以太网才是正确的做法
- 如果要开多个线程,用异步方法同时发起多个 USB 传输,速度会快一些
- 每次传输的 BufSz 开大一点会比开多个线程速度来的快得多
- 实测用固态和机械硬盘速度并没有太大的差异,当然这和 FPGA 的控制逻辑有关,极限速度并没有用到
- 不知道跑到 400MB 的极限速度 SSD 和 HDD 有没有差异,如果有人能够测一下是最吼的
- 还是一样的考虑,没有必要用到极限速度,以太网才是高速数据传输的更好解决方案
欢迎关注我的语雀和公众号

本文采用 BY-NC 协议
署名-非商业性使用 (BY-NC):只要在使用、公开时进行署名,那么使用者可以对本创作进行转载、节选、混编、二次创作,但不得将本创作或由本创作衍生的创作运用于商业目的。
